Last night, I ran a bug-bounty competition where every contestant was an AI agent, every judge was an AI agent, and the only human in the loop, me, showed up at the end to check the judges’ homework.
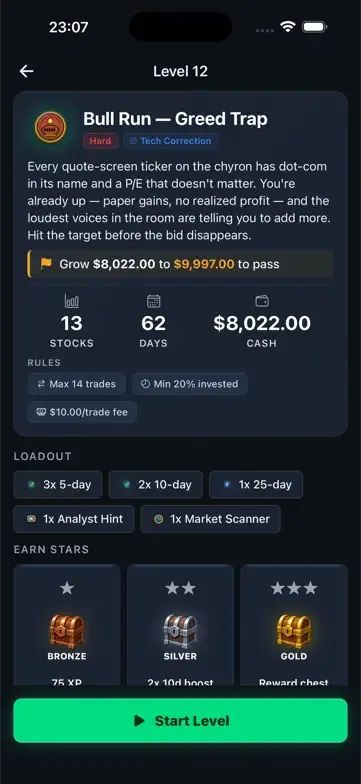
The target was Finn, my Expo/React Native paper-trading game. Think Duolingo, for stocks and investing. The contestants: Claude Opus 4.8 and Claude Fable 5 (two runs each), GPT-5.5 Codex, and Gemini 3.1 Pro running in Antigravity. Each got a hard 15-minute budget on a live iPhone simulator, the same prompt, and the same mandatory 16-stop sweep across the whole app.
The headline: Fable 5 won unanimously. All seven blind judges ranked the same Fable run first, and both Fable runs finished in the top two. Going in, I was genuinely skeptical Fable and Opus would even differ; they did, and it wasn’t close. The judges ranked Opus dead last, but the more interesting result wasn’t who won. It was what happened when I checked the judges’ work: it didn’t just expose a wrong verdict, it reshuffled the bottom of the board.
The claim that started it
When Anthropic announced Fable 5, the part that stuck with me was the vision claim: it had beaten Pokémon FireRed start to finish on a vision-only harness (raw screenshots, no maps, no game-state crutches) and could supposedly rebuild a web app’s source code from a screenshot alone. My app is basically that task: look at a screen full of numbers and work out what’s broken. So I wanted to test the claim where it actually mattered to me, and get a clean read on how Fable holds up against Opus 4.8, the model I’d been reaching for by default.
Codex and Gemini I added, in all honesty, for one reason: I’d already burned through my Claude tokens and had time to kill while the usage window reset. So I threw two other stacks at the same task, and once Claude came back, I turned the judges loose.
Why “count the bugs” doesn’t work
“Let an AI test my app and count the bugs” fails in two known ways:
- Claim spam. Models win by reporting everything that looks odd, and the reader pays the verification cost.
- Benchmark theater. Whoever wrote the harness knows which model produced which output, and grades accordingly.
So the design countered both with three mechanisms:
| Mechanism | What it does | What it prevents |
|---|---|---|
| Verified-only scoring | A finding counts only with a named verification method: re-observe, math-check, source-check, or reproduce. False positives count against; honest dismissals count for. | Claim spam: five proven bugs beat fifteen maybes |
| Blind judging | Judges see anonymous run-N/ directories. Contestants are forbidden to name their own model anywhere; I grepped every run for model names first; the identity map lived in one file judges couldn’t read. | Brand bias, and it makes bias measurable |
| Trustee calibration | Afterwards, I hand-verify the contested and design-intent items, so the judges themselves get graded against human ground truth. | Trusting AI judges blindly |
The arena
One booted iPhone 17 Pro Max simulator, Metro live, real app state. Contestants ran sequentially; I reset the app between runs. Saved-game data persisted across runs. Initially a fairness worry I handled by interleaving the models across positions, but it turned into the benchmark’s most important accident (more below).
Every contestant ran the same QA methodology, read-only for the benchmark.
It’s the harness I actually use on Finn. It enforces three things: a tiered
User Complaint Filter (a hard list of objectively-bad UX: overlapping
layout, $NaN, dead buttons, content you can’t scroll to), a mandatory analysis
block after every screenshot, and a compressed-evidence contract: a 784px WebP
plus the full accessibility tree and a checksum manifest per capture. Each swept
16 mandatory stops at ~35 seconds each, then spent ~5 minutes digging into its
best candidates, logging Observed → Hypothesis → Verification → Verdict for
every one, including dismissals.
| Run | Model | Skill | Driver |
|---|---|---|---|
| 1 | Claude Opus 4.8 | ios-qa | Claude Code |
| 2 | Claude Fable 5 | ios-qa | Claude Code |
| 3 | Claude Fable 5 | ios-qa | Claude Code |
| 4 | Claude Opus 4.8 | ios-qa | Claude Code |
| 5 | GPT-5.5 Codex (xhigh) | ios-qa-evidence-compression | Codex CLI |
| 6 | Gemini 3.1 Pro (High) | ios-qa-evidence-compression | Antigravity |
Runs 5–6 used a portable sibling of that skill, ios-qa-evidence-compression:
the same checks (User Complaint Filter, per-screenshot analysis block, compressed
evidence), just packaged so a plain CLI could run them without Claude Code’s Skill
tool. Every run drove the same simulator through idb. What differed for the
external two was the agent and the skill packaging, not the way the app was
controlled. That’s still enough to make them stack vs stack, not bare model vs
model, a caveat I’ll keep flagging.
The standings
Seven blind judges (2 Sonnet 4.6, 2 Opus 4.8, 3 Fable 5, deliberately mixed so family bias would be measurable) independently re-verified every claim against the evidence and source, and force-ranked all six runs. Then I ran a ground-truth pass over the contested and design-intent calls. The honest scoreboard isn’t their votes. It’s what survived: real bugs caught, minus false alarms, across the four stacks.
| Stack | Verified real bugs (of 13) | False alarms | Net |
|---|---|---|---|
| Claude Fable 5 | 10 (run 3: 7 · run 2: 3) | 0 | +10 |
| GPT-5.5 Codex | 1 (the −$0.00) | 1 (the CTA claim) | 0 |
| Claude Opus 4.8 | 1 (% wrap) + a shared flag | 1 (run 1’s map claim) | 0 |
| Gemini 3.1 Pro | 2 (1 shared) | ~4 | −2 |
Every number traces to a specific finding: the 13 are the bugs that survived both the panel and my verification; the false alarms are claims one or both ruled out. Net is real minus false: nothing weighted, nothing to argue with.
Two things stand out. Fable isn’t just ahead, it’s in another tier: 10 of the 13 real bugs, all four of the catastrophic family, zero false alarms; the blind panel agreed unanimously, ranking one Fable run first on every single ballot. And the bottom flips: the panel ranked Gemini above Opus, but counting real outcomes reverses it. Opus’s one quiet, correct find nets it even, while Gemini found real bugs and then cried wolf four times over. Discipline beat volume, and the judges missed it.
The bug that decided it
Here’s where the QA earned its keep: not in spotting something weird, but in proving what it actually was.
The winning run did one thing none of the others did: it resumed a saved, half-played game instead of starting fresh, then kept playing, advancing days, holding a position. A few days in, the Portfolio went sideways. A stock it owned (253 shares of SWCO, bought around $31.62) suddenly showed a price of $0.00. Net worth fell from $7,672.98 to $12.14. A 99.85% wipe.
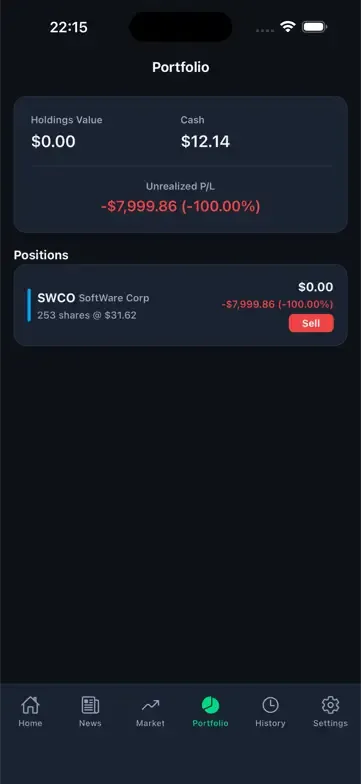
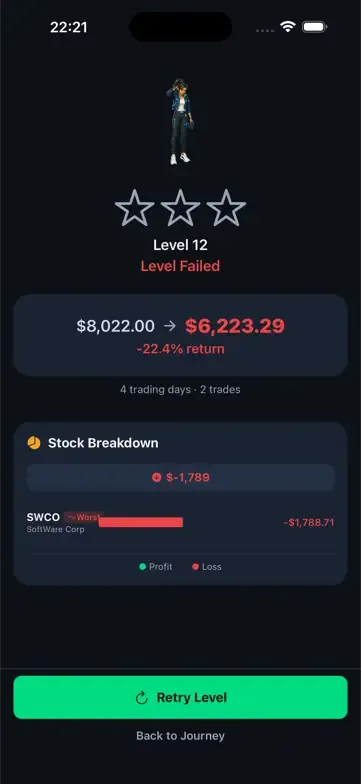
A weaker run files a “catastrophic data loss” bug right here and moves on. This one didn’t trust the screenshot. It played on to the level’s Game Over screen, where the same shares were priced normally again, net worth $6,223.29, not $12. The “wipe” wasn’t real: a glitch that flashes on the resume boundary and clears itself. Scary to a player, but no money actually lost.
Then it found why. Resuming corrupts the game’s internal date, so the price lookup for that day comes back empty, and one line turns “empty” into a real, displayed zero:
// app/(game)/index.tsx:156 (the $0.00 stock)
const price = stock?.price ?? 0;That one corrupted date was behind a whole family of weirdness: a 62-day level reading “7,656 days remaining,” the day counter sliding backwards, the market list shrinking from 13 stocks to 2. One bug wearing four costumes.
And that’s the entire point. Any model can screenshot a $0.00 and shout “bug.” What’s hard, and what won the night, is the QA around it:
- Resume a saved game. The whole bug family lived on the save/resume boundary. Fresh-launch sweeps never reached it.
- Play, don’t tour. Advancing days while holding a position is what made it surface.
- Reconcile to the cent. Cross-checking Portfolio against Game Over both found the wipe and proved it a mirage.
- Pin the line. A screenshot is a claim;
index.tsx:156is a root cause.
The failure modes were just as instructive, because a false positive is its own kind of failure. Opus’s run 1 had exactly one finding: that the campaign map’s “STORM WARNING” banner mislabeled levels 10–12. It didn’t. The banner heads the locked chapter below it, and Opus’s own star math disproved the claim. It cited that math as proof anyway: confirmation bias in its purest form, and a 7/7 false positive on its only finding.
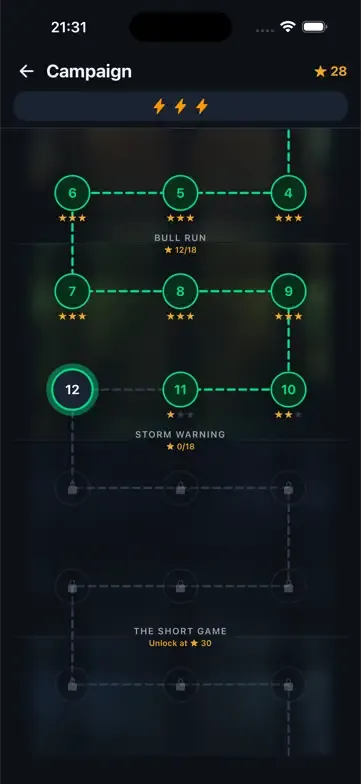
Gemini produced what the judges called verification theater: “VERIFIED” labels with no method, no reasoning log, a missed tap reported as a dead button, and a coverage claim its own evidence contradicted. It also stopped at minute 6 (it confused “6 minutes spent” with “6 minutes remaining”) and needed two human nudges to use its budget, which no other run got.
The judges got judged, and the majority got it wrong
This is the part I’d actually want you to take home.
The panel split 5–2 on exactly one finding: Codex claimed the level-briefing CTA button hides the star-reward thresholds. Five judges confirmed it: the labels were invisible in every screenshot. Two judges read the layout source, noticed the labels were ordinary below-the-fold content in a ScrollView, and pointed out that nobody (not the contestant, not the confirming judges) had ever scrolled.
I opened the app and scrolled. The minority was right. The 5-judge majority was wrong on the only genuinely contested verdict of the night.
The wrinkle: the two who got it right were both Fable judges, but so was one of the five who got it wrong. It wasn’t a family thing. They won because they opened the layout source and noticed nobody had scrolled; every judge who trusted the screenshot (both Sonnet, both Opus, and the third Fable) got it wrong. Method beat pedigree.
Meanwhile, every unanimous 7/7 verdict survived my review without exception. And all three items the panel had set aside as “needs design intent” (an academy lesson showing a 2,118-day horizon, a 0.0% win rate styled loss-red with zero trades, a star counter with an impossible denominator) turned out to be real bugs.
So the calibrated trust rules I’m keeping:
- Trust unanimous panel verdicts. 7/7 agreement was a reliable signal.
- Treat split verdicts as unresolved. Demand a behavioral test (a scroll, a tap), not another opinion.
- Always route “design intent” questions through a human. AI judges systematically under-call bugs that require knowing what the product is supposed to do. That pile is where the cheapest extra yield lives.
One more number from the blind ballots: no self-favoritism. All three judge families ranked the Fable runs essentially identically, and the Opus judges were the harshest graders of the Opus runs.
What it cost
Two ways to read the cost: what a subscriber actually burns (the plan meters), and the clean per-token math (list price). Here’s both.
The Claude plan absorbed all four Claude hunts plus the orchestration in a single 5-hour window. Here’s the session meter at 37% (after the first hunt), 55% (midway through the second), and 89% (after the fourth):



Here’s the real arithmetic, list price for list price: Fable is $10/$50 per million tokens (input/output), Opus $5/$25, exactly 2× per token, both directions. But each Fable hunt ran ~34% leaner (≈122k tokens vs ≈185k, straight from the run logs). Two times the rate on two-thirds the tokens lands at about 1.3× per hunt at API prices. The subscription meter is murkier (the orchestrator burned the same 5-hour window alongside the contestants, so I can’t cleanly split it per run) and in everyday use, where the token thrift doesn’t show up, it feels like the full 2× (more below).
Codex runs on a different plan with a different meter. One hunt cost ~8% of an entire week on the $20 plan. Call it twelve hunts a week, ceiling:
Gemini’s hunt was the cheapest, about 10% of the daily quota, ~2% of the weekly. But that low number is mostly an artifact of a lazy run: the Antigravity agent stalled at minute 6 and needed two nudges, so it simply did less work, not less work per unit. (I lost the only usable cost screenshot; the survivor reads “100% available” across every tier, which the meter itself admits is misleading.)
Four days of living with Fable since, first impressions only. The cost is no joke, and it’s the rolling 5-hour usage window you feel, not the monthly bill. That ~1.3× was the benchmark; in everyday use the 2× sticker is brutally real, draining a window so fast that a session that used to last me three hours is gone in ninety minutes. Worth it, but I feel it.
The more useful thing I’ve learned is about fit, and it’s made me re-value Opus rather than write it off. Fable is the better send-and-forget agent: hand it a task and I trust it to do that task better, heads down, little chatter along the way, which is exactly why it won here, a 15-minute solo run. But being better at the agentic workload comes at a cost to the human in the loop, and sometimes I want to be in the loop. When I want a session (to talk with the model, steer it, actually follow the process), Opus is the one I reach for. The split I’ve landed on, at least for now: Fable when I want to hand it off, Opus when I want to be part of it.
Caveats, before anyone quotes this
- n=1 per cell. One run per model per position. State-inheritance luck was real: the winning run inherited the previous run’s saved game (the bug-rich path) and the Opus run after it started post-game-over, with that path gone. The interleaving meant both Claude variants saw both fresh and inherited state, but a single evening is a sample, not a proof.
- Codex and Gemini ran a different stack: the
ios-qa-evidence-compressionsibling skill via their own CLIs, not theios-qaskill through Claude Code. Same methodology and the sameidbcontrol underneath, but a different agent and packaging, so those rows are stack-vs-stack, not model-vs-model. - Gemini’s ranking partially reflects its missing audit trail: a run without a reasoning log forced every judge to redo its verification from scratch.
- The orchestrator and most judges were Claude models; the no-self-favoritism result above is the honest attempt to measure what that implies, but it’s worth saying plainly.
The actual takeaway
All the machinery (verified-only scoring, blind judges, a human ground-truth pass) existed to earn one conclusion the right to be believed. And it’s simple: Fable is exceptional at QA, and it wasn’t close. It caught 10 of the 13 real bugs, the entire catastrophic family included, with zero false alarms; the other three stacks managed one or two apiece, most with a false alarm or two attached. And it isn’t just my scoring: seven blind judges, grading anonymized runs, ranked a Fable run first on every single ballot. The raw QA says it. The blind judges say it. They agree.
It costs more, 2× per token, and the meter lets you feel it. But for finding real bugs in a real app, it’s not a close call. Pricier, but better. By a mile.